
Hi again. This is Dung Dao Minh, vice president of SoICT Innovation Club, and in this third post of series “Github 101”, I will talk about some kind of scenarios that can happen when you work on multiple branches in your work repositories, or work in collaboration with a team on a project.
First words
In many cases, you (and your collaborators) create multiple branches for different purpose: creating features, bug fixing, code versioning,… Most of the issues happen when you try to combine the code between those branches: you may realize that you still commit to the main branch while fixing bugs/adding features, another developer may add a little documentation on your code (which is great), or your evil coworker might mess up with your code and make it full of bugs. In short, there may be some modification on the branch you are trying to merge into, that you need to resolve to (happily) combine the two different commits.
I will create (with additional references from other sources) some different scenarios here that represent the problem you might face when working on different branches, and make it easy to introduce some new definition, as well as some good practices when working with Git and Github
Scenario #1: Working on new feature (no file conflict yet)
Suppose that you are working on a project about real estate recommendation system, and you want to try using location information for your system. In the middle of your work, your boss want you to focus 100% of your time on improving system based on demographic information.
Step 1: assume that you are on the develop branch. You should create a new branch location for developing the new feature:
# Create and switch to new branch
git checkout -b location
# Commit as you go
git commit -m "add recommendation based on city'
Step 2: however, you boss want you to focus on demographic features. You have not completed the location feature yet
# Switch back to the develop branch
git checkout develop
# Create and switch to `demographic` branch
git checkout -b demographic
# Working on that branch and commit changes
git commit -m "finalized demographic-based recommendation"
Step 3: after you finish your work on demographic feature, you can merge it to the develop branch and push this to the remote origin/develop branch (assuming that both develop and origin/develop have no additional commit in the mean time)
# Switch back to the develop branch
git checkout develop
# Merge the `demographic` branch into the `develop` branch
git merge --no-ff demographic
# Push to the remote repository
git push origin develop
Quick note on merge: fast-forward vs. no fast-forward
You might see the --no-ff (no fast-forward) in the step 3 above. The new demographic code seems to only add new code, without any modification.
A picture is worth a thousand words:
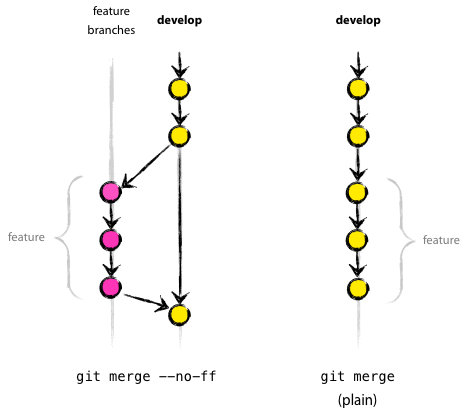
--no-ff will create a new commit (with new id, but the file content is the same), while by default, git merge will fast-forward - moving your branch pointer (in this case, at develop) to point at the incoming commit (from demographic).
Note: when you merge with --no-ff, as a new commit is created, you might be asked to create message for that commit.
In many cases, you want to prevent fast-forward from happening, because you want to maintain a specific branch “shape”, and someone (your manager) can read the history of changes that you made from creating the demographic branch (instead of losing information when fast-forward)
You can change you command or do some setups to merge with or without feed-forward:
# Execute for once: add the `--ff-only`, or `--no-ff` flag
# Apply for both pull and merge (pull = fetch + merge)
git pull --ff-only
git pull --no-ff
# Using git config to do it by default
# (git pull or git merge won't need specific flag)
git config --add merge.ff false
git config --add merge.ff only
Scenario #2: Same file names, different file contents on different branches (conflict)
You might wonder what’s the purpose of the location branch created above. Now I will use it to demonstrate merge conflict.
In a bad mood, you forgot that you create that location branch for experimenting with location data, and you do some commit directly on the develop branch to work with that data. Let review some of the recent commits you made (notice the HEAD->location (current branch) at commit f3b1b57 and the develop branch at commit 9a5187c)
git log --graph --decorate --oneline --all
* 9a5187c (develop) add recommendation based on city in develop
* 1fe34c7 Merge branch 'demographic' into develop
|\
| * 0883fd7 (demographic) finalized demographic-based recommendation
|/
| * f3b1b57 (HEAD -> location) add recommendation based on city
|/
* b3a463a (origin/develop) Create develop branch
For simple demonstration purpose, here are the 2 versions of location.txt on that 2 branches:
# On `develop` branch
location file in develop
# On `location` branch
location file
Some ways you might consider to resolve the conflict
When you realize the mistake, there are some cases here:
Case 1: You recognize that there are part of the features you develop from both branches would be useful, and you want to combine them together.
Run the command git merge develop will create the following message:
Auto-merging location.txt
CONFLICT (add/add): Merge conflict in location.txt
Automatic merge failed; fix conflicts and then commit the result.
This is inevitable, since the 2 files have different contents inside. Inside the location.txt file, you can see that the content has been modified. The upper part is the line of the current commit pointed by HEAD and the lower part is the
<<<<<<< HEAD
location file
=======
location file in develop
>>>>>>> develop
Check git status for additional understanding:
On branch location
You have unmerged paths.
...
Unmerged paths:
(use "git add <file>..." to mark resolution)
both added: location.txt
To resolve the problem, simply modify the location.txt file as you wish (obviously, you don’t want those “«<” or “===” characters anyway) and add it to the staging area, then create a new commit. Here I will modify the text into “location file after resolve conflict”:
git add location.txt
git status
# On branch location
# All conflicts fixed but you are still merging.
# ...
git commit -m "resolve conflict in location feature"
git log --graph --decorate --oneline --all
# Now we see that the `location` branch has new commit
* 1f79c56 (location) resolve conflict in location feature
|\
| * 9a5187c (HEAD -> develop) add recommendation based on city in develop
| * 1fe34c7 Merge branch 'demographic' into develop
Case 2: You have done a far better work in the develop branch, and you don’t need the same code on location branch anymore. Or the other way around, you soon realize the mistake, and the location branch has more valuable code
The obvious solution is to use the code in develop instead of that code on location, or the other way around. You can use the approach in Case 1, observing that in some IDE, they support you with choosing the respective version you want. An example in VSCode (you can accept either change or both changes):
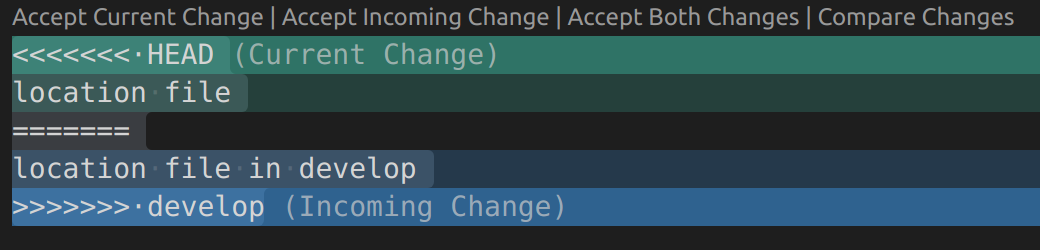
A quicker way is to use additional flags, in favor of one of the branch (ours strategy refer to preference of the current branch, and theirs is the preference of the incoming branch):
git merge --strategy=ours develop
git merge -X theirs develop
Note: -s or --strategy completely ignore the other side, while -X or --strategy-option resolve any conflicts using the chosen side.
Additional note: merge vs rebase, and options for git pull
Perhaps some animation is great here (acknowledgement to Nicola Paolucci’s post with the animations). Click on animated images to see how it works:

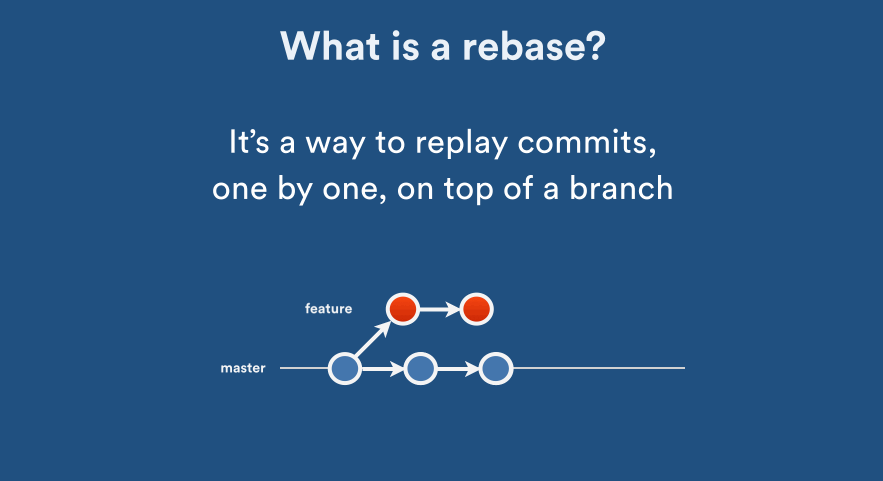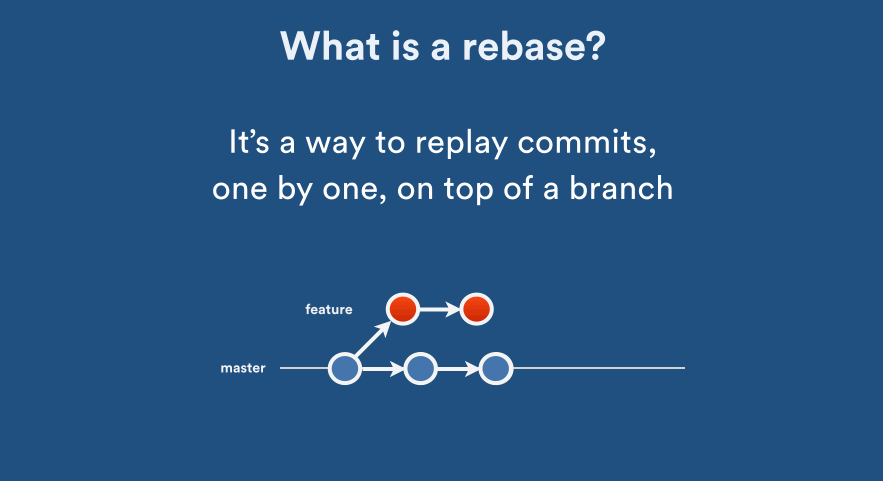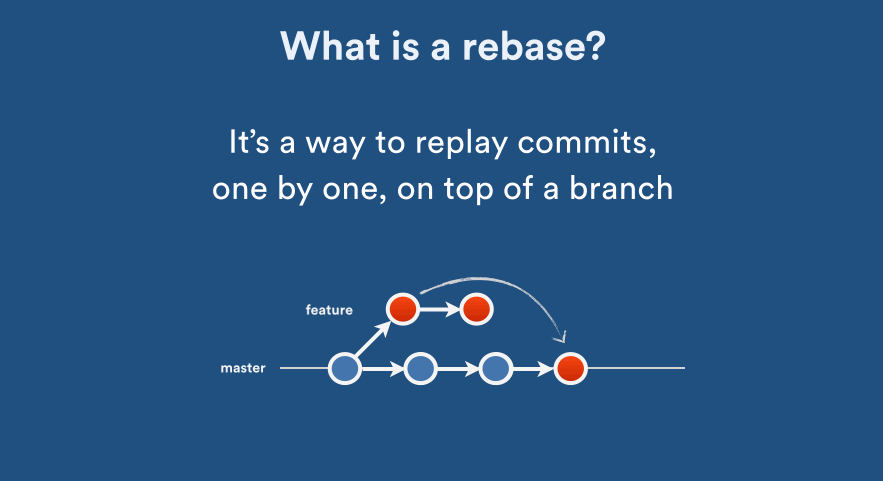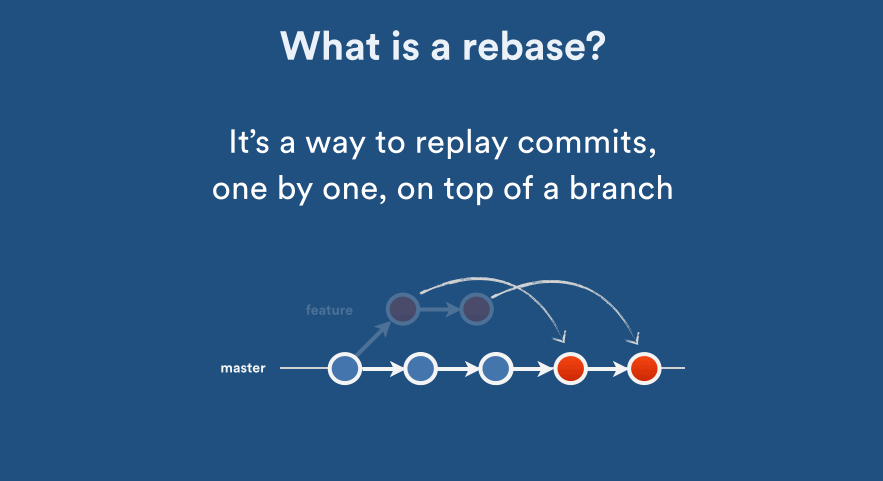
You should use git rebase when your changes do not “deserve” a separate branch for its own. All the commands with merge above can also be done with rebase; note that it has a different behaviour as in the animations
When working with remote directories, if you want to rebase instead of merge after fetching changes, you can add --rebase flag to the pull command:
git pull=git fetch+git mergeagainst tracking upstream branchgit pull --rebase=git fetch+git rebaseagainst tracking upstream branch
Final words
The conflict in reality can be more complex, but in this episode, I have list the common cases you might face when you need to merge 2 branches together.
There are some images in the post, some are mine, some are from the Internet, and it’s free to use as in the LICENSE below. But I always leave credit here to support authors, and so do you if you want to use content in my article.
- A scenario from the Udacity’s Machine Learning DevOps Engineer helps me a lot in creating a bunch of scenarios above: https://www.udacity.com/course/machine-learning-dev-ops-engineer-nanodegree--nd0821
- Answers on StackOverflow that help me with explanation (and images) in the process:
- https://stackoverflow.com/questions/9069061/what-effect-does-the-no-ff-flag-have-for-git-merge
- https://stackoverflow.com/questions/18930527/difference-between-git-pull-and-git-pull-rebase
- https://stackoverflow.com/questions/173919/is-there-a-theirs-version-of-git-merge-s-ours
- https://stackoverflow.com/questions/2500296/can-i-make-fast-forwarding-be-off-by-default-in-git
- Amazing images and explanations from Nicola Paolucci’s blog post: https://blog.developer.atlassian.com/pull-request-merge-strategies-the-great-debate/